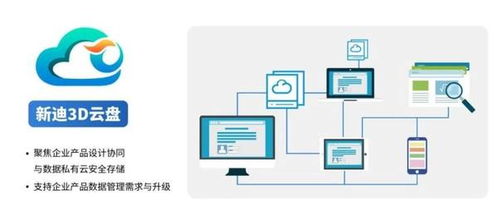
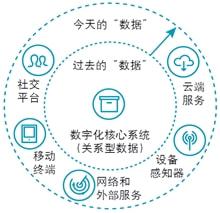
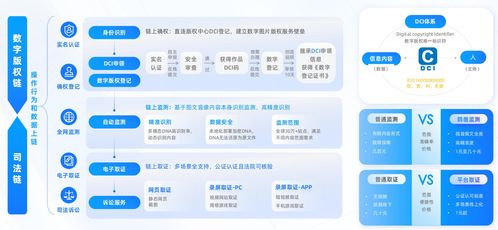
Hadoop的历史 数字技术的演进服务
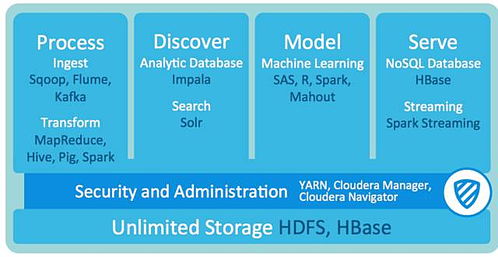
Hadoop是当今大数据处理领域的基石技术之一,其发展历程深刻反映了数字技术服务的演进。Hadoop的起源可追溯到2002年,当时Apache Nutch项目面临网页索引数据量激增的挑战。受Google在2003年和2004年发布的MapReduce和Google File System(GFS)论文启发,Doug Cutting和Mike Cafarella开始开发一个分布式计算框架,并以其儿子玩具大象的名字命名为'Hadoop'。
2006年,Hadoop正式成为Apache软件基金会的顶级项目,标志着其开源生态的建立。随着数字经济的兴起,Hadoop迅速被Yahoo、Facebook等科技巨头采用,用于处理海量用户数据,提供高效的搜索、广告推荐等数字服务。其核心组件HDFS(分布式文件系统)和MapReduce(并行处理模型)解决了传统数据库无法应对的PB级数据存储与计算问题。
2010年后,Hadoop生态系统不断扩展,涌现出HBase、Hive、Pig等工具,进一步推动了云计算、物联网和人工智能等数字技术服务的发展。例如,企业利用Hadoop分析用户行为数据,优化个性化服务;政府机构借助其处理公共数据,提升智慧城市管理效率。
尽管近年来新兴技术如Spark和云原生方案部分替代了Hadoop的角色,但Hadoop的历史贡献不可磨灭。它不仅是开源文化的典范,更奠定了现代数据驱动型数字服务的基础,从电子商务到医疗健康,无处不在的数字化应用都受益于其分布式架构思想。未来,Hadoop的遗产将继续影响下一代大数据技术的创新,助力全球数字经济的持续变革。
如若转载,请注明出处:http://www.tmhvtfj.com/product/22.html
更新时间:2026-06-19 16:31:20